360° Attention

Everyone needs attention, even an LLM
The attention mechanism allows an LLM to identify what is relevant within a sequence, which largely explains its impressive performance. However, while it revolutionized the field a few years ago, it is also the primary driver of significant computational and memory costs. Google Research recently unveiled TurboQuant, a method designed to compress the attention cache.
The Attention Cache?
During the generation phase (producing tokens one by one), recalculating attention over the entire context at each step would be computationally prohibitive. To optimize this, the model stores the projections of previous tokens in what is known as the KV Cache (Key-Value Cache). While this mechanism reduces computational complexity, it shifts the burden to memory: the size of these key and value matrices grows linearly with both the sequence length and the number of simultaneous requests (batch size). This represents the primary bottleneck that saturates GPU VRAM.
Cache is Money
The idea is simple: instead of reading matrices using Cartesian coordinates, we use polar coordinates. To put it simply, instead of saying “Go 3 blocks east and 4 blocks north,” we say “Go 5 blocks at a 37° angle” (PolarQuant).
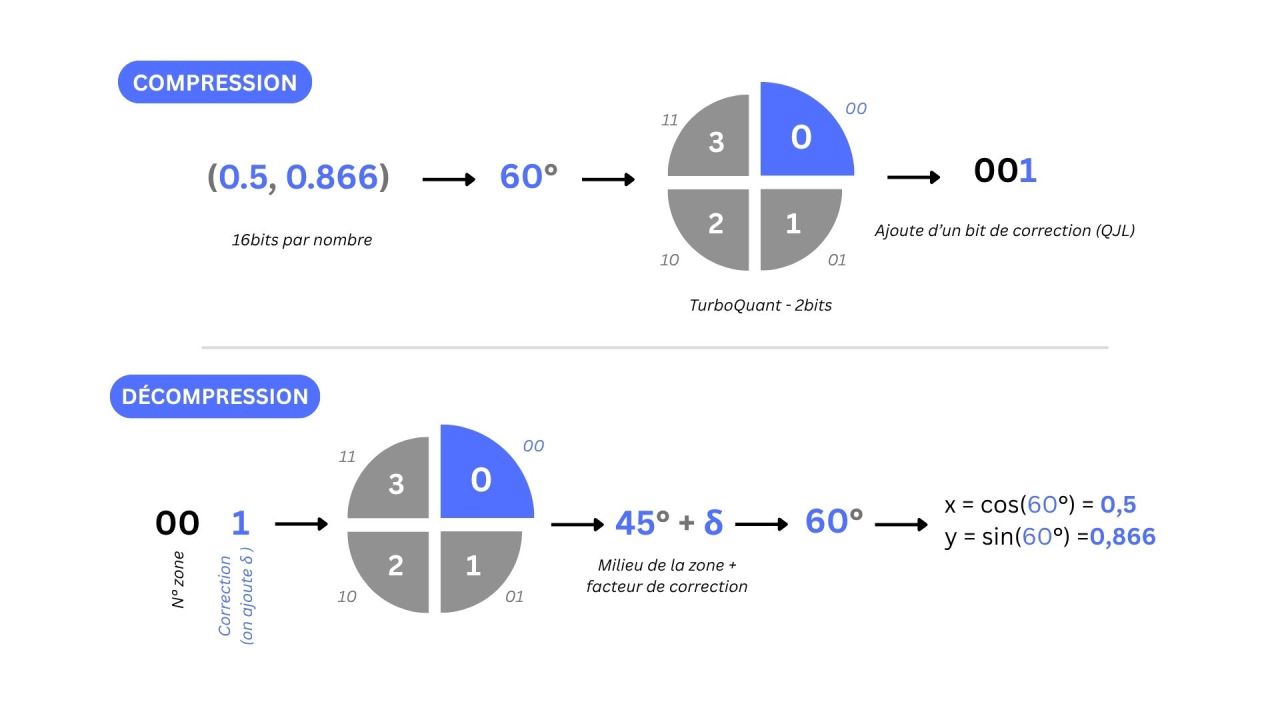
This reformulation allows the essence of the information—the vector's direction—to be captured using very few bits. A correction mechanism (QJL) then compensates for the most significant quantization errors. The result is a significant reduction in RAM usage and processing time, achieved without any meaningful loss in performance.
📚 Sources
- TurboQuant: Redefining AI efficiency with extreme compression. March 24, 2026 Amir Zandieh, Research Scientist, and Vahab Mirrokni, VP and Google Fellow, Google Research