A Security Agent for Your Network? Reinforcement Learning for Detecting Anomalies in Network Traffic

Our daily lives are becoming increasingly digital, and computer networks continue to grow in both size and complexity. The traffic they carry is becoming denser and more diverse: banking transactions, health data, private communications, etc.
With the rise of so-called intelligent technologies — smart homes, smart cities, personalized medicine — the number of connected devices is expected to exceed 50 billion by the end of 2025. These devices, though ubiquitous, are often poorly secured: neglected updates, weak passwords, outdated protocols.
In this context, computer networks are prime targets for cybercriminals, who benefit from an ever-expanding attack surface. Designing effective and robust cybersecurity solutions has thus become a critical challenge — a fast-moving research field, but also an increasingly complex one.
Detecting Anomalies
By analyzing network traffic, it is possible to detect behavioral deviations that may conceal cyberattacks. When we talk about network traffic, we generally refer to flows, which group packets that share common characteristics.
A flow can be defined by a set of properties such as IP addresses, ports, transport protocol, duration, size, etc., but also by more abstract characteristics like the number of packets, the average packet size, and so on.
Anomaly detection is a well-established field, with early approaches dating back several decades. Signature-based methods were the first anomaly detection systems (IDS). They work by comparing network traffic to a database of known attack signatures and raising an alert if there's a match. However, these methods are limited to detecting only known attacks, cannot adapt to new threats, and are not robust to slight variations.
Quickly, machine and deep learning-based approaches were introduced: by learning from historical data, they overcome these limitations, detect more complex anomalies and generalize to unknown flows.
Network Behavior Evolves
As with any learning system, the quality and relevance of the data used play a fundamental role — this also applies to network traffic. In addition to the standard preprocessing pipeline, it is crucial to ensure that flows remain representative of the network's current behavior so that the model's inferences stay relevant over time.
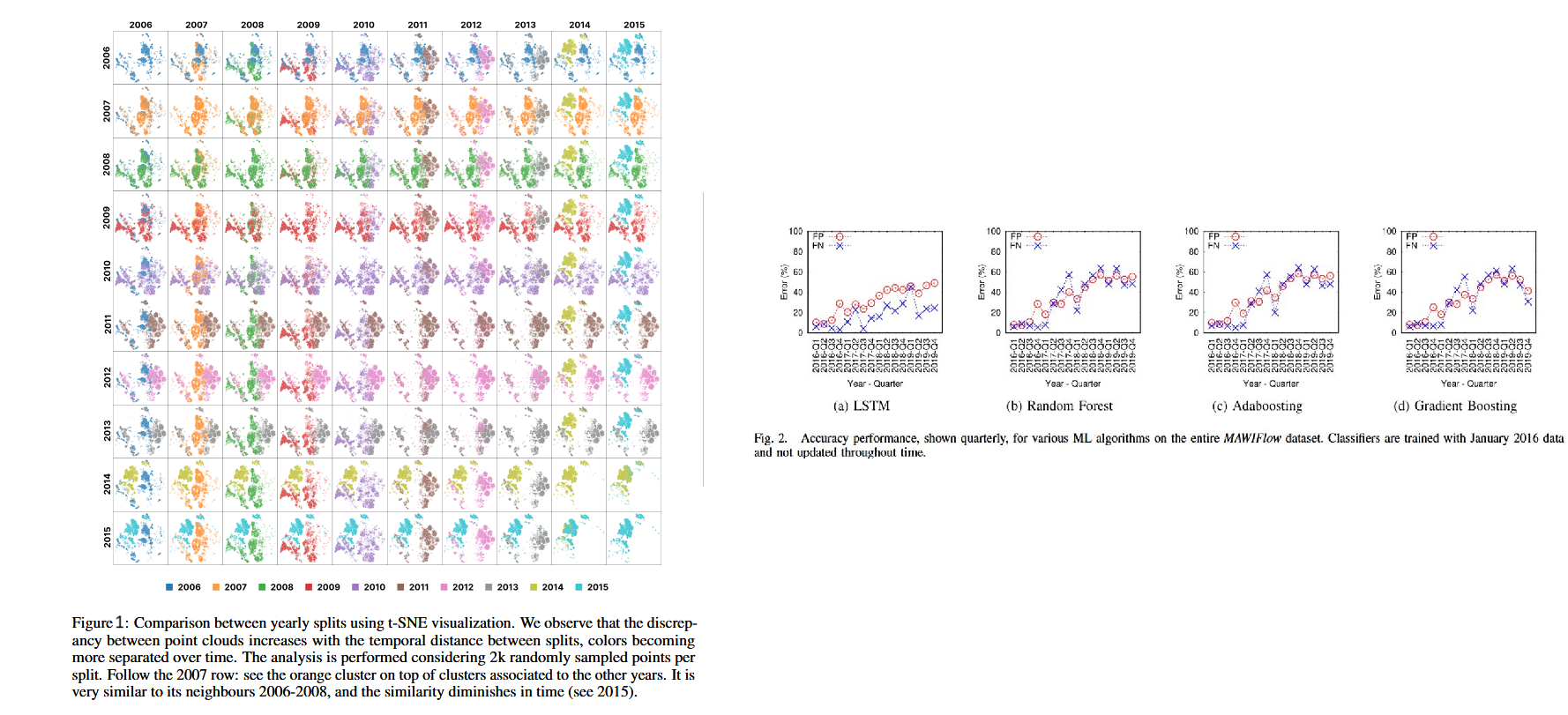
Dragoi, Marius, et al. showed that as time passes (Figure 1), network traffic behavior evolves significantly. Santos Roger, on the other hand, highlighted the increasing error rates of various anomaly detection models over time if they are not retrained (Figure 2).
All this illustrates the concept drift phenomenon and the need to retrain anomaly detection models regularly to ensure that traffic modeling stays accurate and detection remains effective.
Reinforcement Learning
But regularly retraining a model requires time, computational resources, and frequent human involvement in data labeling and deciding when to retrain.
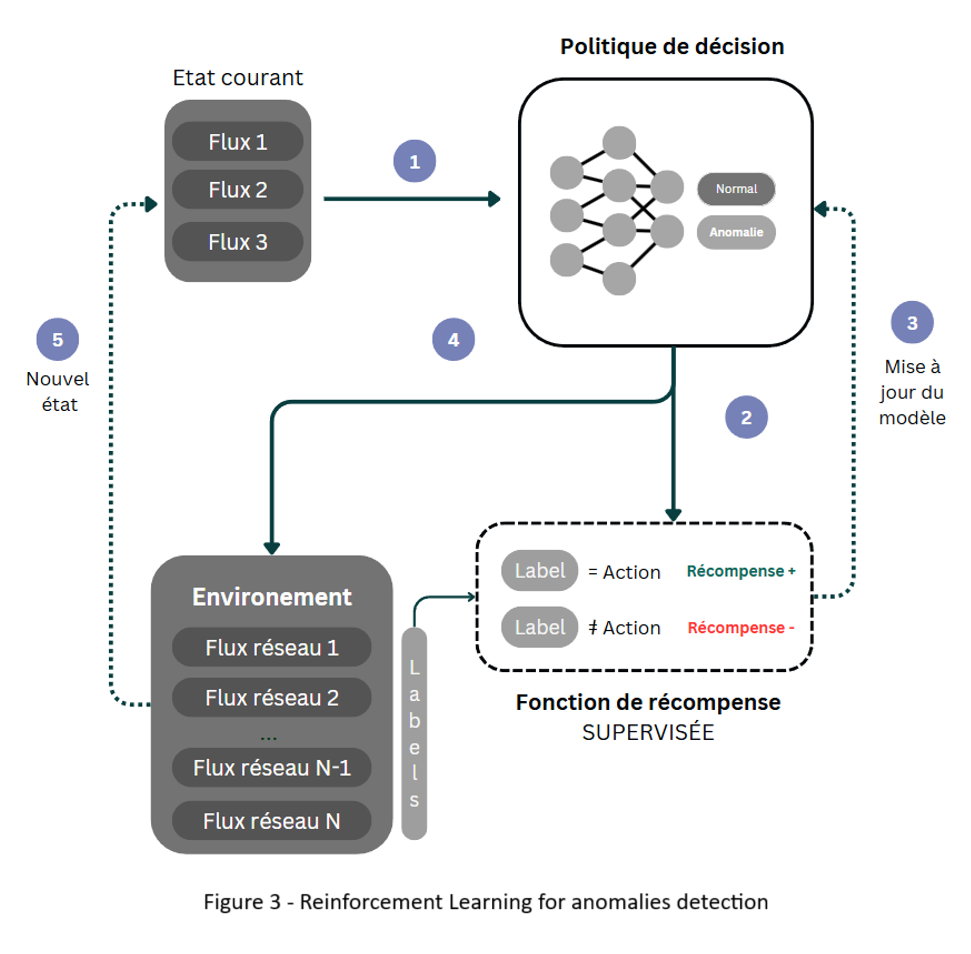
Reinforcement learning, a branch of machine learning, offers a different approach. It learns through interactions with its environment and receives rewards or penalties based on its actions. With the goal of maximizing future rewards, it learns to optimize its decisions over time.
When applied to anomaly detection — or other domains with very large state spaces — a neural network is used to approximate the value function, which evaluates the quality of actions taken by the agent in a given state.
The environment is defined by the network traffic observed by the agent. It takes actions (such as raising an alert or not) and receives rewards based on the relevance of its actions.
A Reward Function for Realistic Use Cases
The reward function lies at the heart of reinforcement learning. It guides the agent toward desired behaviors. In the context of anomaly detection, the reward function must be carefully designed to reflect security goals and operational priorities.
If the reward function is too simplistic, the agent may learn undesirable behaviors, and the goal of maximizing reward can work against us — this is known as the Cobra Effect.
In colonial India under British rule, the government offered a reward for every dead cobra to eradicate the infestation. Instead of decreasing, the population began to breed cobras in order to kill them and collect the money.
In our case, if the agent receives a large reward for every alert it raises, it might become overly sensitive and constantly raise alerts to collect rewards, leading to a high number of false positives.
The reward function is not inherently part of the environment: it is up to the agent designer to define it carefully, choosing precisely when a reward should be granted and what it truly represents.
Introducing additional knowledge into the reward function can help the agent converge faster — this is known as Reward Shaping.
Most of the time in state-of-the-art approaches, reward functions are based on labeled data, which prevents the agent from learning continuously and autonomously in a real environment.
In my work, I focus on designing a reward function that would allow the agent to learn from new, unlabeled traffic — notably by relying on clustering techniques that would help agents adapt to new traffic patterns without human supervision. But I’ll probably have the chance to dive deeper into that in a future post 😉
📚 Sources
- Dragoi, Marius, et al. "Anoshift: A distribution shift benchmark for unsupervised anomaly detection." Advances in Neural Information Processing Systems 35 (2022): 32854-32867.
- Reinforcement Learning for Intrusion Detection: More Model Longness and Fewer Updates - Santos Roger 2022
- Huang and al. ‘Deep Learning Advancements in Anomaly Detection: A Comprehensive Survey” (2025)
- Tawalbeh, Lo’ai, et al. "IoT Privacy and security: Challenges and solutions." Applied Sciences 10.12 (2020): 4102.
- Khraisat, Ansam, et al. "Survey of intrusion detection systems: techniques, datasets and challenges." Cybersecurity 2.1 (2019): 1-22.