Un agent de sécurité pour nos réseaux ? L’apprentissage par renforcement pour détecter les anomalies dans le trafic réseau

Notre quotidien se numérise rapidement, et les réseaux informatiques ne cessent de croître en taille et en complexité. Le trafic qu’ils transportent est de plus en plus dense et varié : transactions bancaires, données de santé, communications privées, etc. Avec l’essor des technologies dites intelligentes — smart homes, smart cities, médecine personnalisée — le nombre d’objets connectés devrait dépasser les 50 milliards d’ici fin 2025. Ces dispositifs, bien qu’omniprésents, sont souvent peu sécurisés : mises à jour négligées, mots de passe faibles, protocoles obsolètes. Dans ce contexte, les réseaux informatiques représentent une cible de choix pour les cybercriminels, qui profitent d’une surface d’attaque en constante expansion. Concevoir des solutions de cybersécurité efficaces et robustes devient ainsi un enjeu crucial, un champ de recherche particulièrement dynamique, mais aussi un défi de plus en plus complexe.
Détecter une anomalie
En analysant le trafic, il est possible de détecter des déviations de comportement pouvant cacher des cyber attaques. Lorsqu’on parle de trafic réseau, on fait généralement référence à des flux (ou flows), qui regroupent des paquets partageant des caractéristiques communes. Un flux peut être défini par un ensemble de propriétés comme les adresses IP, les ports, le protocole de transport, la durée, la taille, etc. mais aussi par d'autres propriétés comme le nombre de paquets, la taille moyenne des paquets, etc. La détection d’anomalies est un domaine bien établi, dont les premières approches remontent à plusieurs décennies. Les méthodes par signature ont été les premiers systèmes de détection d'anomalies (IDS). Elles consistent à comparer le trafic réseau à une base de données de signatures connues d'attaques et à lever une alerte s'il y a un match. Cependant, ces méthodes sont limitées par leur capacité à détecter uniquement les attaques connues, ne peuvent pas s'adapter aux nouvelles menaces et ne sont pas robustes aux légères variations. Rapidement, les méthodes basées sur le machine et le deep learning ont été introduites : en apprenant sur des données historiques elles surmontent ces limitations, détectent des anomalies plus complexes et parviennent à généraliser à des flux encore jamais observés.
Le comportement sur le réseau change
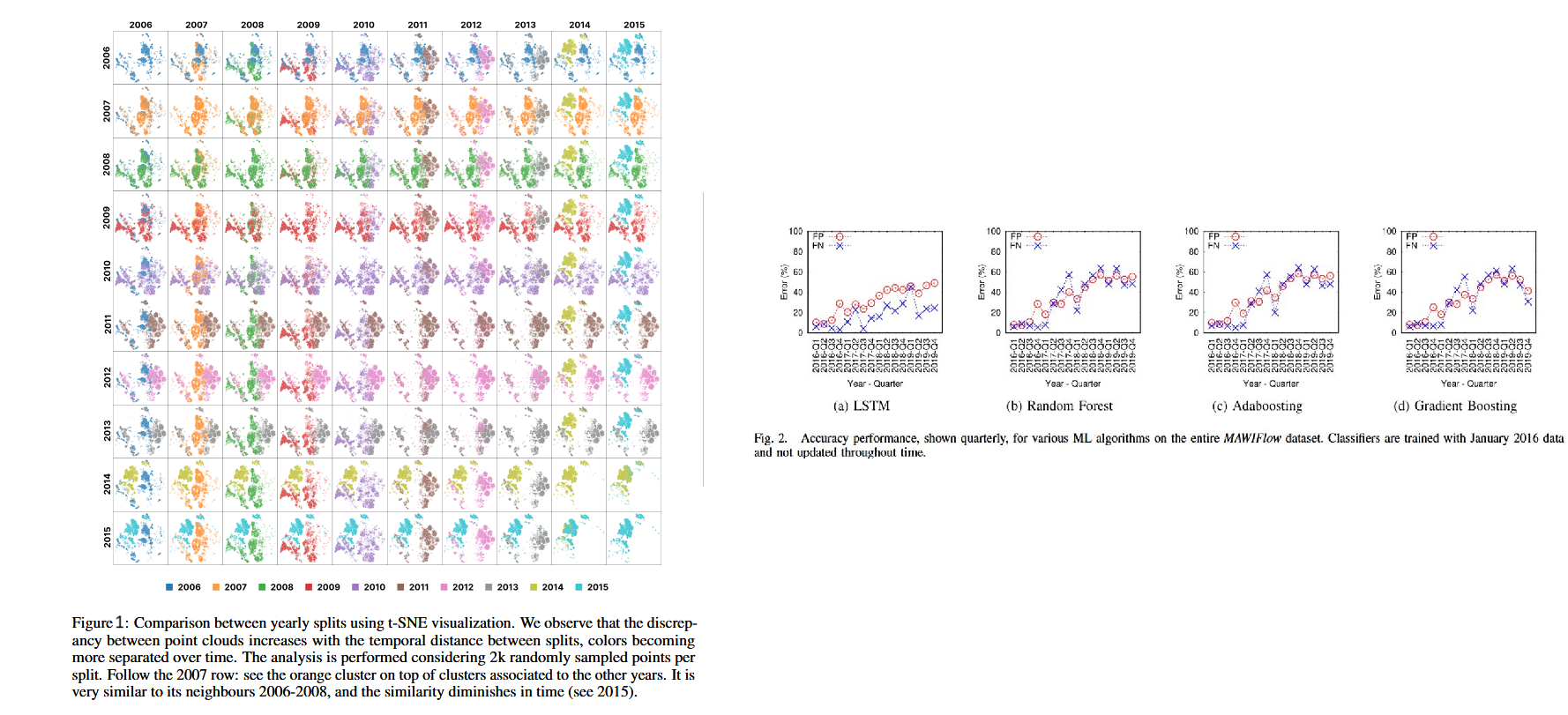
Comme pour tout système d’apprentissage, la qualité et la pertinence des données utilisées jouent un rôle fondamental et cela vaut également pour le trafic réseau. En plus de la pipeline de préparation classique, il faut s'assurer que les flows soient représentatifs du comportement actuel du réseau pour que les inférences du modèle restent pertinentes sur le long terme. Dragoi, Marius, et al. ont montré que plus les années passaient (Figure 1), plus le comportement du trafic réseau évoluait. Santos Roger quant à eux mettent en avant l'augmentation des erreurs de différents modèles de détection d'anomalies au fur et à mesure du temps s'ils ne sont pas ré-entraînés (Figure 2). Tout cela met en avant le phénomène de concept drift et la nécessité de ré-entraîner les modèles de détection d'anomalies régulièrement pour que la modélisation du trafic soit correcte, actuelle et que la détection reste pertinente.
L'apprentissage par renforcement
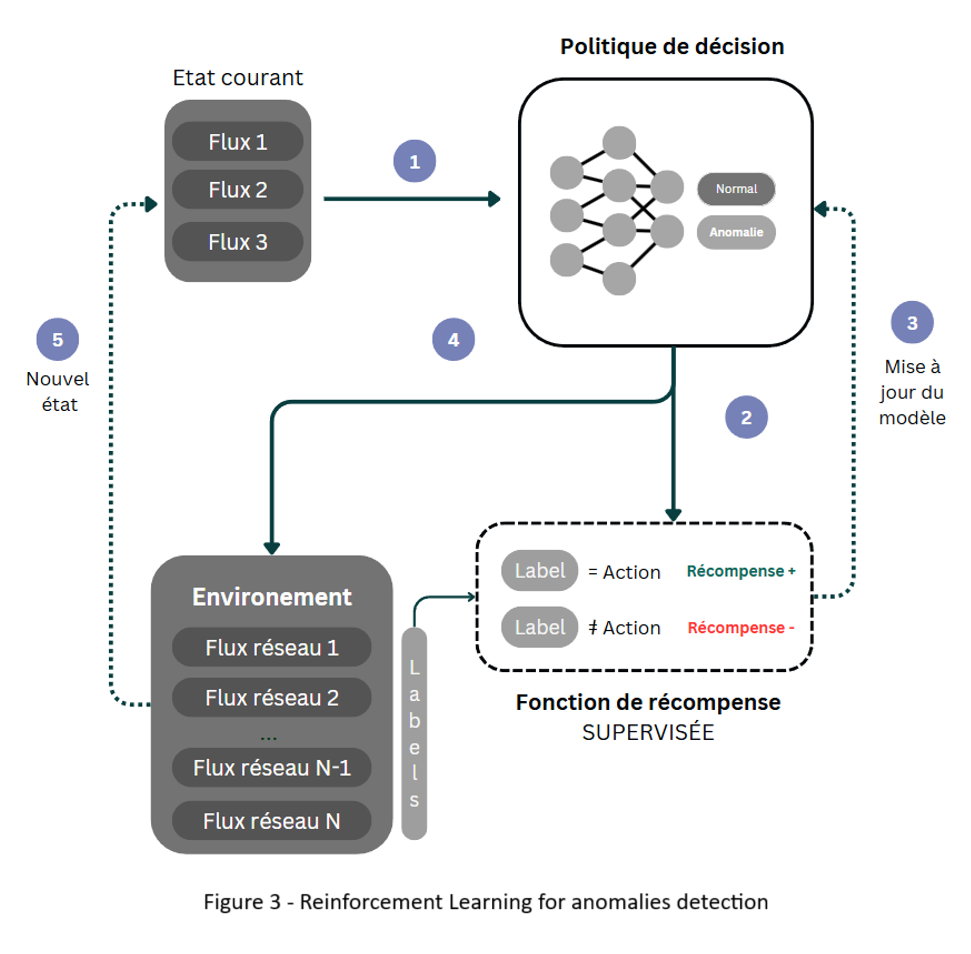
Mais entraîner régulièrement un modèle demande du temps, de la puissance de calcul et une implication humaine régulière dans le choix et l'étiquetage des données et le choix des moments opportuns auxquels il faut s'entraîner. L'apprentissage par renforcement, une branche du machine learning, propose une approche différente. Il apprend à partir d'interactions avec l'environnement et reçoit des récompenses ou des pénalités en fonction de ses actions. En ayant comme objectif de maximiser les récompenses futures, il va apprendre à optimiser ses décisions au fil du temps. Lorsqu'il est appliqué à la détection d'anomalies, ou d'autres domaines dans lesquels l'espace des états est très grand, un réseau de neurones est utilisé pour approximer la fonction de valeur, qui évalue la qualité des actions prises par l'agent dans un état donné. L'environement est défini par le trafic réseau que l'agent observe. Il prend des actions (comme lever une alerte ou non) et reçoit des récompenses en fonction de la pertinence de ses actions.
Une fonction de récompense pour des cas d'usage réalistes
La fonction de récompense est alors au coeur de l'apprentissage par renforcement. Elle guide l'agent vers des comportements souhaités. Dans le contexte de la détection d'anomalies, la fonction de récompense doit être soigneusement conçue pour refléter les objectifs de sécurité et les priorités opérationnelles. Si la fonction de récompense est trop simple, l'agent peut apprendre des comportements indésirables et l'objectif de maximisation de la récompense peut jouer en notre défaveur, c'est ce qu'on appelle l'effet Cobra.
Dans les anciennes colonies britanniques en Inde, le gouvernement a offert une récompense pour chaque cobra mort afin d’éradiquer leur infestation. Au lieu de diminuer, la population a commencé à élever des cobras pour les tuer ensuite et toucher l’argent.
Dans notre cas, si l'agent reçoit une récompense trop grande pour chaque alerte levée, il peut devenir trop sensible et constamment lever des alertes pour obtenir un maximum de récompense, ce qui entraînerait de nombreux faux positifs. La fonction de récompense ne fait pas partie intégrante de l’environnement : c’est au concepteur de l’agent de la définir avec soin, en choisissant précisément les situations dans lesquelles une récompense doit être attribuée, et ce qu’elle représente réellement.
Introduire des connaissances supplémentaires dans la fonction de récompense peut aider l'agent à converger plus rapidement, on parle de Reward Shaping.
La plupart du temps dans l'état de l'art, les fonctions de récompenses sont basées sur des étiquettes empêchant l'agent d'apprendre en continue et de manière autonome dans un environnement réel. Dans mes travaux, je me penche sur l'élaboration d'une fonction de récompense qui permettrait à l'agent d'apprendre sur du trafic nouveau et sans étiquettes, notamment en s'appuyant sur des techniques de clustering qui permettraient à des agents de s’adapter aux nouvelles formes de trafic sans supervision humaine, mais j’aurai sûrement l’occasion d’y revenir plus en détail plus tard 😉
📚 Sources
- Dragoi, Marius, et al. "Anoshift: A distribution shift benchmark for unsupervised anomaly detection." Advances in Neural Information Processing Systems 35 (2022): 32854-32867.
- Reinforcement Learning for Intrusion Detection: More Model Longness and Fewer Updates - Santos Roger 2022
- Huang and al. ‘Deep Learning Advancements in Anomaly Detection: A Comprehensive Survey” (2025)
- Tawalbeh, Lo’ai, et al. "IoT Privacy and security: Challenges and solutions." Applied Sciences 10.12 (2020): 4102.
- Khraisat, Ansam, et al. "Survey of intrusion detection systems: techniques, datasets and challenges." Cybersecurity 2.1 (2019): 1-22.