Une attention à 360°

On a tous besoin d'attention, même un LLM
Le mécanisme d’attention permet à un LLM d’identifier ce qui est pertinent dans une séquence, et explique en grande partie ses performances impressionnantes. Mais s’il a révolutionné son domaine il y a quelques années, il est aussi le principal responsable d’un important coût de calcul et de mémoire. Google Research a récemment dévoilé TurboQuant, une méthode permettant de compresser le cache d’attention.
Le cache d'attention ?
Lors de la phase de génération (la production des tokens un par un), recalculer l'attention sur l'intégralité du contexte à chaque étape serait beaucoup trop lourd. Pour optimiser ça, le modèle stocke les projections des tokens précédents dans ce qu'on appelle le KV Cache (Key-Value Cache). Si ce mécanisme permet de réduire la complexité de calcul, il déplace le problème vers la mémoire : la taille de ces matrices de clés et de valeurs croît linéairement avec la longueur de la séquence et le nombre de requêtes simultanées (batch size). C'est le principal goulot d'étranglement qui sature la VRAM des GPU.
Le cache c'est de l'argent
L’idée est simple : au lieu de lire les matrices en utilisant des coordonnées cartésiennes, on utilise des coordonnées polaires. Pour faire simple, au lieu de dire “Avance de 3 blocs à l’est et 4 au nord” on dit “Avance de 5 blocs avec un angle de 37°” (PolarQuant).
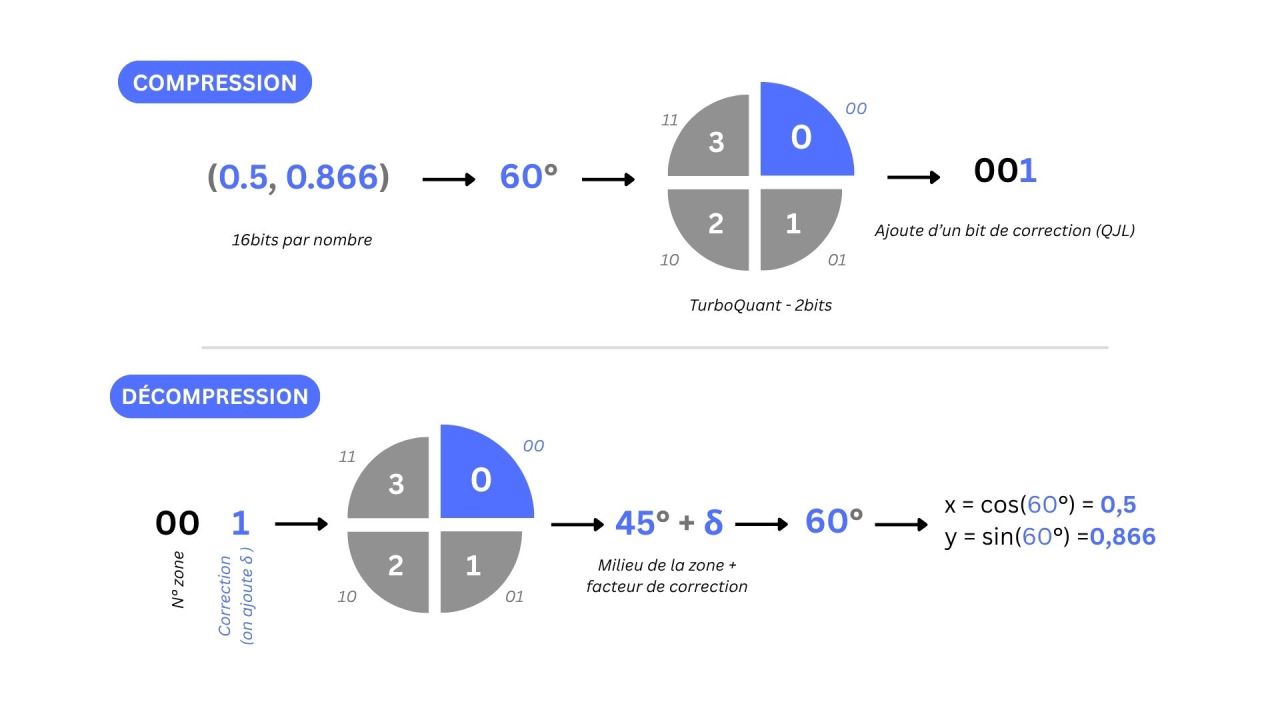
Cette reformulation permet de capturer l’essentiel de l’information (la direction du vecteur) avec très peu de bits. Un mécanisme de correction (QJL) vient ensuite compenser les erreurs de quantification les plus importantes. On économise de la RAM et du temps tout sans perte significative de performance.
📚 Sources
- TurboQuant: Redefining AI efficiency with extreme compression. March 24, 2026 Amir Zandieh, Research Scientist, and Vahab Mirrokni, VP and Google Fellow, Google Research