Stackoverflow est mort ? Les LLMs aussi ?

Ce n'est aujourd'hui plus un secret, les LLMs ont besoin d'énormément de données textuelles pour être entrainés efficacement. De part son volume immense, le web est rapidement devenu la source de données principale et la majorité des datasets d'entraînements se basent aujourd'hui dessus. En plus de la quantité stratosphérique de données, la diversité des sources est également un facteur clé pour garantir une bonne couverture des différents styles d'écriture, sujets et contextes. Parmi ces sources, les forums de développeurs comme Stackoverflow jouent un rôle crucial. Mais ces dernières années, l'activité sur Stackoverflow a connu une baisse significative, soulevant des questions sur son avenir et son impact potentiel sur les futurs entraînements des LLMs.
Stackoverflow, une mine d'or de données
En effet, Stackoverflow est une plateforme incontournable pour les développeurs du monde entier. Elle permet aux programmeurs de poser des questions techniques, pragmatiques et parfois très précises. Les réponses fournies par la communauté sont souvent détaillées, incluant des extraits de code, des explications approfondies et des solutions pratiques à des problèmes courants.
Stackoverflow est l'une des plateformes les plus populaires où les développeurs partagent leurs connaissances, posent des questions techniques et fournissent des solutions détaillées à une variété de problèmes de programmation.
On n'y trouve pas uniquement des réponses à des questions mais aussi des discussions autour des bonnes pratiques, des recommendations d'outils, des conseils pour optimiser le code ect. Ce sont des réelles discussions, des cheminements de pensées, des réflexions collaboratives développées et documentées par les paires. Cela en fait une mine d'or pour l'entraînement des modèles de langage, en particulier ceux axés sur la programmation. Dans le dataset RedPajama, Stackoverflow représente à lui seul plus de 7% des données, faisant de lui une source principale pour l'entraînement des LLMs aux problèmes de programmation [2].
Pourquoi utiliser Stackoverflow quand j'ai déjà chatGPT ?
Quand j'étais étudiant, Stackoverflow était ma référence quand mon code ne fonctionnait pas. Ce que je trouvais fascinant, c'est que tous mes problèmes avaient déjà été rencontrés, discutés et résolus par quelqu'un d'autre avant moi. Même si ce n'était pas exactement le même contexte ou l'exact même erreur, avec un peu de réflexion et de débrouille j'arrivais à faire fonctionner mon programme. Mais aujourd'hui, je n'aurais même plus besoin de tout ça, j'aurais presque même pas besoin de réfléchir car un LLM comme GPT-4 ou Claude pourrait cerner mon problème et me générer un code complet et adapté à mon problème en quelques secondes ! Cependant, adopter cette réflexion c'est prendre le risque d'exposer notre code à des erreurs subtiles, des biais ou des vulnérabilités de sécurité que nous ne pourrions pas détecter sans une compréhension approfondie du code généré. Zhong & Wang [1] se sont penchés sur la question en se demandant si les LLMs pouvaient remplacer Stackoverflow. Ils ont évalué la capacité de plusieurs LLMs à répondre à des questions extraites de Stackoverflow concernant des API Java dites complexes et ont comparé leurs performances à celles des réponses fournies par la communauté. Les résultats montre qu'avec GPT-4, dans + de 60% des cas, le code contient des erreurs d'utilisation d'API. Seuls l'ajout d'exemples montrant l'utilisation correcte de l'API permettait d'avoir de meilleurs résultats (in-context learning). En effet, du code exécutable n'est pas forcément du code fiable et même si de meilleurs résultats peuvent être obtenus avec un meilleur prompt, tous les utilisateurs ne sont pas sensibilisé à cela et ne sont pas forcément capables de fournir ce contexte additionnel.
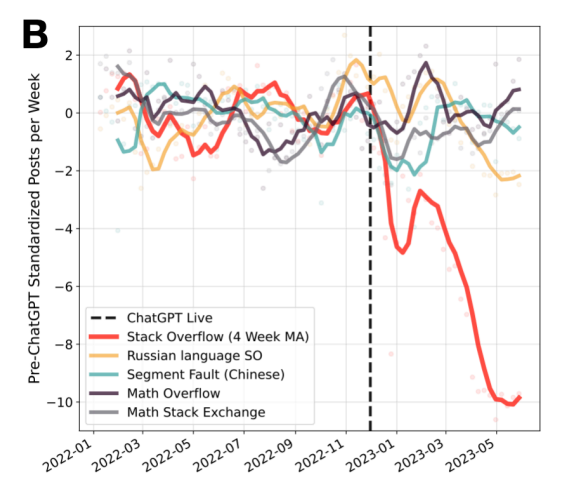
Comparaison des publications sur Stack Overflow, ses équivalents russes et chinois, et les plateformes de questions-réponses mathématiques depuis début 2022 [3].
Qui utilise encore Stackoverflow ?
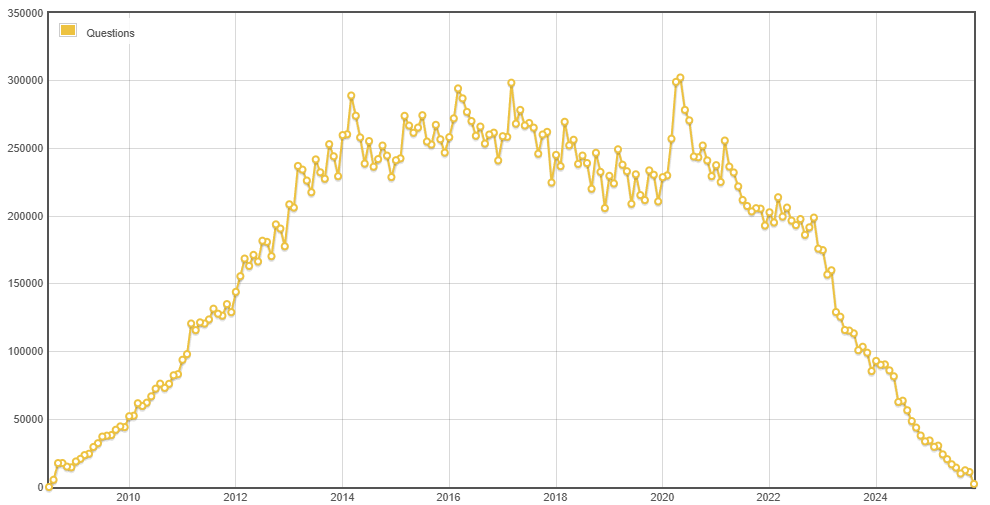
Dès la sortie de ChatGPT, l'activité sur Stackoverflow a brutalement chuté de 16% et depuis c'est de pire en pire : en Mai 2022 on comptait +200 000 questions posées sur Stackoverflow, en Octobre dernier on en compte 11 116 seulement soit une baisse de 94% en un peu plus de 3 ans [4] contrairement à d'autres équivalents ou plateformes spécialisées (image ci-dessus). Il faut donc noter plusieurs choses :
- Les LLMs sont à priori assez bon en code pour répondre à la majorité des questions posées sur Stackoverflow sur des langages populaires [3].
- De plus en plus de développeurs veulent une réponse rapidement et privilégient les LLMs pour résoudre leurs problèmes, avec les risques que cela comporte.
- Moins de questions posées signifie moins de données de qualité pour les futurs entraînements des LLMs.
Pour le second point, on en a discuté précédemment et les discours autour de la dépendance grandissante aux LLMs sont très nombreux, je vais vous épargner ça. Mais cette baisse d'activité sur Stackoverflow est très préoccupante pour l'avenir des LLMs. En effet, comme mentionné précédemment, Stackoverflow est une source précieuse de données de haute qualité pour l'entraînement des modèles de langage. Moins de questions et de réponses signifie moins de données pour entraîner les futurs modèles, ce qui pourrait potentiellement affecter leur performance et leur capacité à comprendre et résoudre des problèmes futurs complexes. D'une part, les LLMs seront moins bons sur de futurs nouveaux langages ou librairies, mais d'une autre part les développeurs ne s'en aperceveront pas et continueront d'utiliser les LLMs potentiellement plus sujets à des hallucinations et donc à produiront du code faux. Mais Stackoverflow et d'autres forums restent toujours actifs notamment sur des langages moins populaires [3], non maitrisés par les LLMs mais pour combien de temps ?
📚 Sources
- Zhong, L., & Wang, Z. (2024, March). Can llm replace stack overflow? a study on robustness and reliability of large language model code generation. In Proceedings of the AAAI conference on artificial intelligence (Vol. 38, No. 19, pp. 21841-21849).
- Perełkiewicz, M., & Poświata, R. (2024, June). A review of the challenges with massive web-mined corpora used in large language models pre-training. In International Conference on Artificial Intelligence and Soft Computing (pp. 153-163). Cham: Springer Nature Switzerland.
- del Rio-Chanona, M., Laurentsyeva, N., & Wachs, J. (2023). Are large language models a threat to digital public goods. Evidence from activity on stack overflow. arXiv, 2307.
- StackExchange - Stackoverflow. https://data.stackexchange.com/stackoverflow/query/1882534/questions-per-month#graph